# 4.1. scrapy_redis实现增量式爬虫
# 目标
- 了解scarpy_redis的概念和功能
- 了解scrapy_redis的实现流程
- 掌握scrapy_redis增量式爬虫的实现方法
# 1. scrapy_redis是什么
Scrapy_redis : Redis-based components for Scrapy.
Github地址:https://github.com/rmax/scrapy-redis (opens new window)
在这个地址中存在三个demo,后续我们对scrapy_redis的学习会通过这三个demo展开
# 2. 为什么要学习scrapy_redis
Scrapy_redis在scrapy的基础上实现了更多,更强大的功能,具体体现在:
- 请求对象的持久化
- 去重的持久化
- 和实现分布式
# 3. scrapy_redis的原理分析
# 3.1 回顾scrapy的流程

那么,在这个基础上,如果需要实现分布式,即多台服务器同时完成一个爬虫,需要怎么做呢?
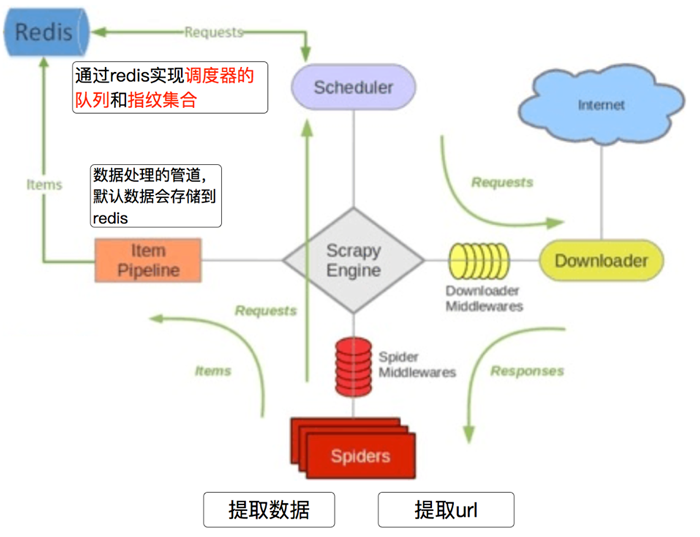
# 3.2 scrapy_redis的流程
- 在scrapy_redis中,所有的带抓取的对象和去重的指纹都存在所有的服务器公用的redis中
- 所有的服务器公用一个redis中的request对象
- 所有的request对象存入redis前,都会在同一个redis中进行判断,之前是否已经存入过
- 在默认情况下所有的数据会保存在redis中
具体流程如下:
# 4. 对于redis的复习
# 4.1 redis是什么
redis是一个开源的内存型数据库,支持多种数据类型和结构,比如列表、集合、有序集合等
# 4.2 redis服务端和客户端的启动
/etc/init.d/redis-server start启动服务端redis-cli -h -p <端口号>客户端启动
# 4.3 redis中的常见命令
select 1切换dbkeys *查看所有的键tyep 键查看键的类型flushdb清空dbflushall清空数据库
# 4.4 redis命令的复习
redis的命令很多,这里我们简单复习后续会使用的命令

# 5. scrapy_redis domz爬虫 分析
# 5.1 拷贝源码中的demo文件
1、clone github scrapy-redis源码文件 git clone https://github.com/rolando/scrapy-redis.git 2、研究项目自带的三个demo mv scrapy-redis/example-project ~/scrapyredis-project
# 5.2 观察dmoz文件
在domz爬虫文件中,实现方式就是之前的crawlspider类型的爬虫
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class DmozSpider(CrawlSpider):
"""Follow categories and extract links."""
name = 'dmoz'
allowed_domains = ['dmoztools.net']
start_urls = ['http://dmoztools.net/']
# 定义数据提取规则,使用了css选择器
rules = [
Rule(LinkExtractor(
restrict_css=('.top-cat', '.sub-cat', '.cat-item')
), callback='parse_directory', follow=True),
]
def parse_directory(self, response):
for div in response.css('.title-and-desc'):
yield {
'name': div.css('.site-title::text').extract_first(),
'description': div.css('.site-descr::text').extract_first().strip(),
'link': div.css('a::attr(href)').extract_first(),
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
但是在settings.py中多了一下几行,这几行表示scrapy_redis中重新实现的了去重的类,以及调度器,并且使用的RedisPipeline
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
SCHEDULER_PERSIST = True
ITEM_PIPELINES = {
'example.pipelines.ExamplePipeline': 300,
'scrapy_redis.pipelines.RedisPipeline': 400,
}
2
3
4
5
6
7
8
# 5.3 运行dmoz爬虫,观察现象
首先我们需要添加redis的地址,程序才能够使用redis
REDIS_URL = "redis://127.0.0.1:6379" #或者使用下面的方式 # REDIS_HOST = "127.0.0.1" # REDIS_PORT = 63791
2
3
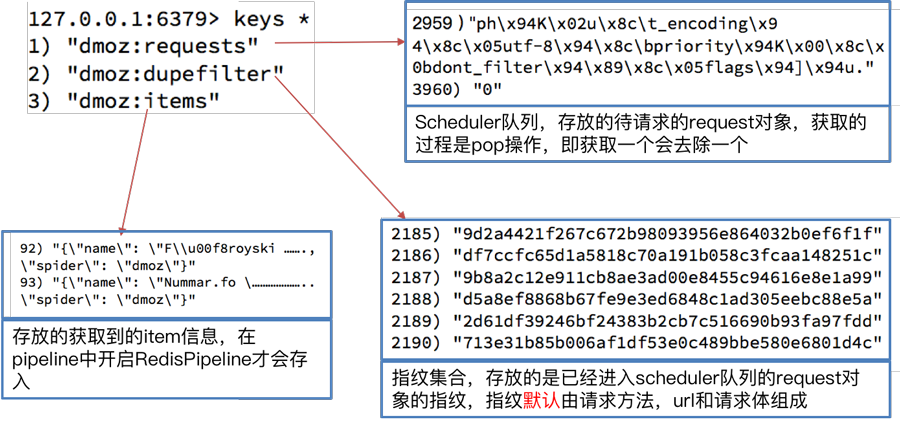
4我们执行domz的爬虫,会发现redis中多了一下三个键:
继续执行程序
继续执行程序,会发现程序在前一次的基础之上继续往后执行,所以domz爬虫是一个基于url地址的增量式的爬虫
# 6. scrapy_redis的原理分析
我们从settings.py中的三个配置来进行分析 分别是:
RedisPipeline
RFPDupeFilter
Scheduler
# 6.1 Scrapy_redis之RedisPipeline
RedisPipeline中观察process_item,进行数据的保存,存入了redis中

# 6.2 Scrapy_redis之RFPDupeFilter
RFPDupeFilter 实现了对request对象的加密

# 6.3 Scrapy_redis之Scheduler
scrapy_redis调度器的实现了决定什么时候把request对象加入带抓取的队列,同时把请求过的request对象过滤掉

由此可以总结出request对象入队的条件
- request之前没有见过
- request的dont_filter为True,即不过滤
- start_urls中的url地址会入队,因为他们默认是不过滤
# 7. 动手
- 需求:抓取京东图书的信息
- 目标:抓取京东图书包含图书的名字、封面图片地址、图书url地址、作者、出版社、出版时间、价格、图书所属大分类、图书所属小的分类、分类的url地址
- url:https://book.jd.com/booksort.html (opens new window)
思路分析:
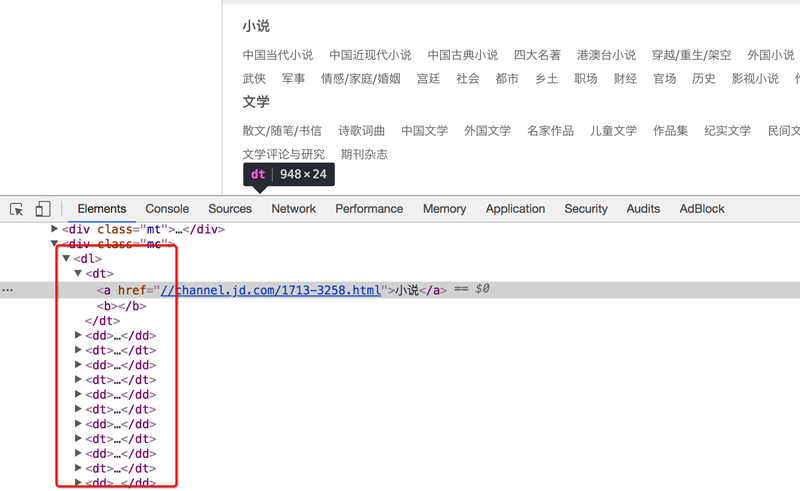
确定数据抓取的入口
数据都在dl下的dt和dd中,其中dt是大分类的标签,dd是小分类的标签
对应的思路可以使选择所有的大分类后,选择他下一个兄弟节点即可
xpath中下一个兄弟节点的语法是
following-sibling::*[1]
确定列表页的url地址和程序终止的条件
有下一页
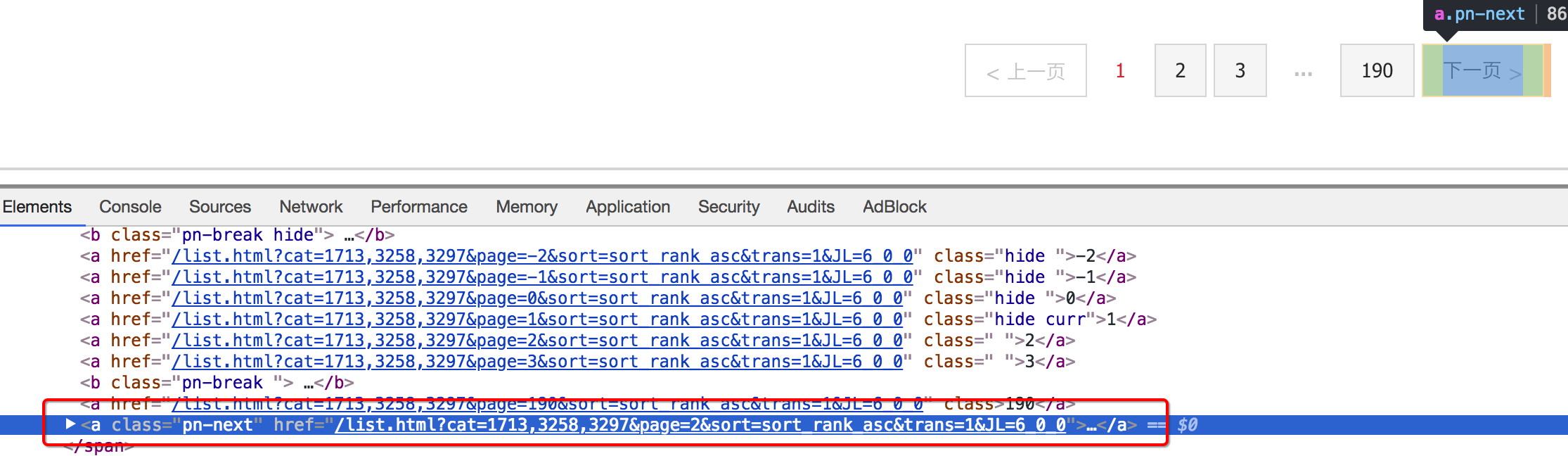
没有下一页
确定数据的位置
数据大部分都在url地址的响应中,但是价格不在
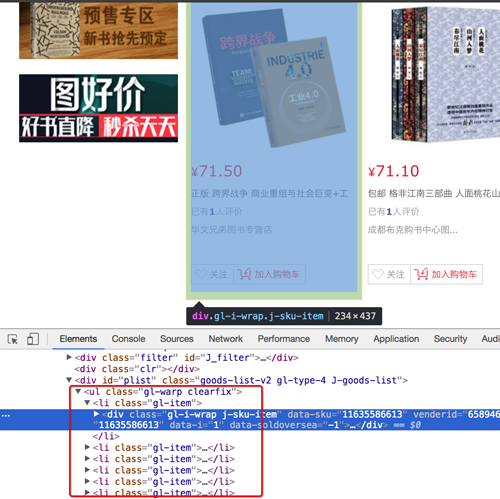
通过search all file的方法,找到价格的地址,

对url地址进行删除无用的参数和url解码之后,获取到价格的url为
https://p.3.cn/prices/mgets?skuIds=J_11635586613
其中skuId为商品的id,能够在网页中获取
- 使用scrapy的思路完成爬虫,在settings中添加上scrapy_redis的配置
# 总结
- 本小结重点
- 知道什么是scrapy_redis
- 掌握scarpy_redis实现分布式的原理
- 掌握scrapy_进行url地址加密的方法
- 掌握request对象入队的条件
- 能够通过scrapy_redis完成基于url地址的增量式爬虫