# 3.4. scrapy的深入使用
# 目标
- 认识scrapy的debug信息
- 知道scrapy shell如何使用
- 认识setting中的配置一起配置的使用
# 1. 认识scrapy的debug信息
每次程序启动后,默认情况下,终端都会出现很多的debug信息,那么下面我们来简单认识下这些信息

# 2. scrapy shell的使用
scrapy shell是scrapy提供的一个终端工具,能够通过它查看scrapy中对象的属性和方法,以及测试xpath
使用方法:scrapy shell http://www.itcast.cn/channel/teacher.shtml
在终端输入上述命令后,能够进入python的交互式终端
小知识点:
- response.url:当前响应的url地址
- response.request.url:当前响应对应的请求的url地址
- response.headers:响应头
- response.body:响应体,也就是html代码,默认是byte类型
- response.requests.headers:当前响应的请求头
# 3. 认识scrapy中的setting文件
- 为什么项目中需要配置文件
- 在配置文件中存放一些公共变量,在后续的项目中便便修改,注意其中的变量名一般全部大写
- 配置文件中的变量使用方法
- 导入即可使用
settings.py中的重点字段和内涵USER_AGENT设置uaROBOTSTXT_OBEY是否遵守robots协议,默认是遵守CONCURRENT_REQUESTS设置并发请求的数量,默认是16个DOWNLOAD_DELAY下载延迟,默认无延迟COOKIES_ENABLED是否开启cookie,即每次请求带上前一次的cookie,默认是开启的DEFAULT_REQUEST_HEADERS设置默认请求头SPIDER_MIDDLEWARES爬虫中间件,设置过程和管道相同DOWNLOADER_MIDDLEWARES下载中间件
# 4. 管道中的open_spider和close_spider 的方法
在管道中,除了必须定义process_item之外,还可以定义两个方法:
open_spider(spider):能够在爬虫开启的时候执行一次close_spider(spider):能够在爬虫关闭的时候执行一次
所以,上述方法经常用于爬虫和数据库的交互,在爬虫开启的时候建立和数据库的连接,在爬虫关闭的时候断开和数据库的连接
下面的代码分别以操作文件和mongodb为例展示方法的使用:


# 5. 动手
需求:爬取苏宁易购所有下所有图书和图书分类信息,以及子链接页面的价格内容。
url : https://book.suning.com/ (opens new window)
思路分析:
确定数据抓取的入口 数据包含一个大分类,每个大分类包含多个中间分类,每个中间分类包含多个小分类
注意其中中间分类的位置并不在大分类中,小分类的位置也不在中间分类中
大分类的位置如下:
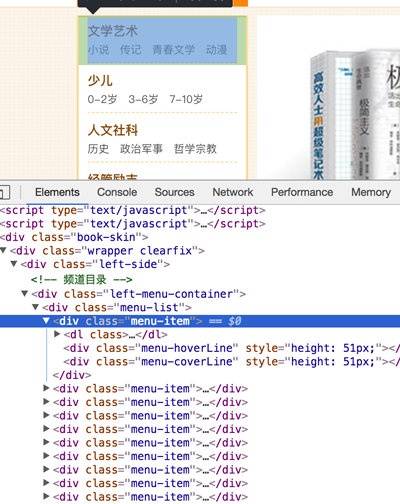
中间分类和小分类的位置如下:
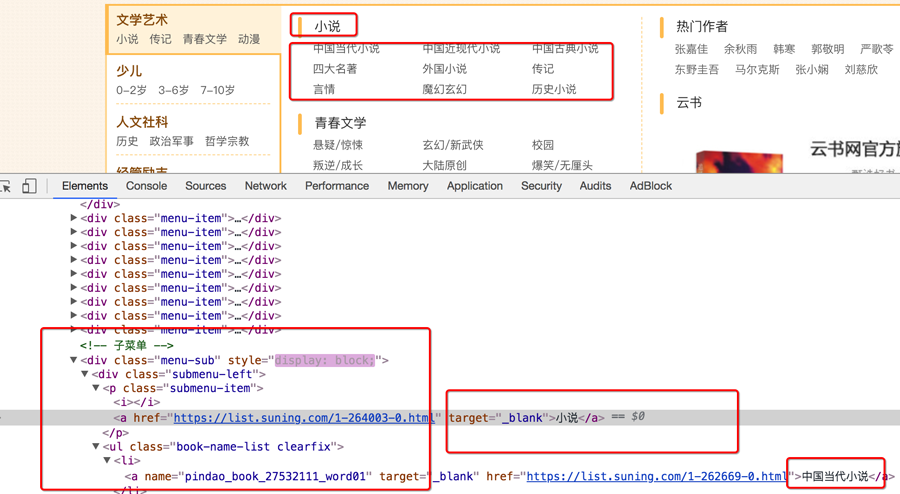
确定url和程序终止的条件 列表页首页的地址就是小分类的地址,通过请求这些地址,能够进入列表页的首页
但是翻页的url地址不在响应中,而且每个页面的数据是由两个请求获取的
通过抓包,能够知道URL地址的规律,pagenum每次+1

那么如果确定什么时候程序终止呢?
通过观察url地址对应的响应,能够知道总的页码数和当前页码数,当前页码数<总的页码数时,能够构造出下一页的请求
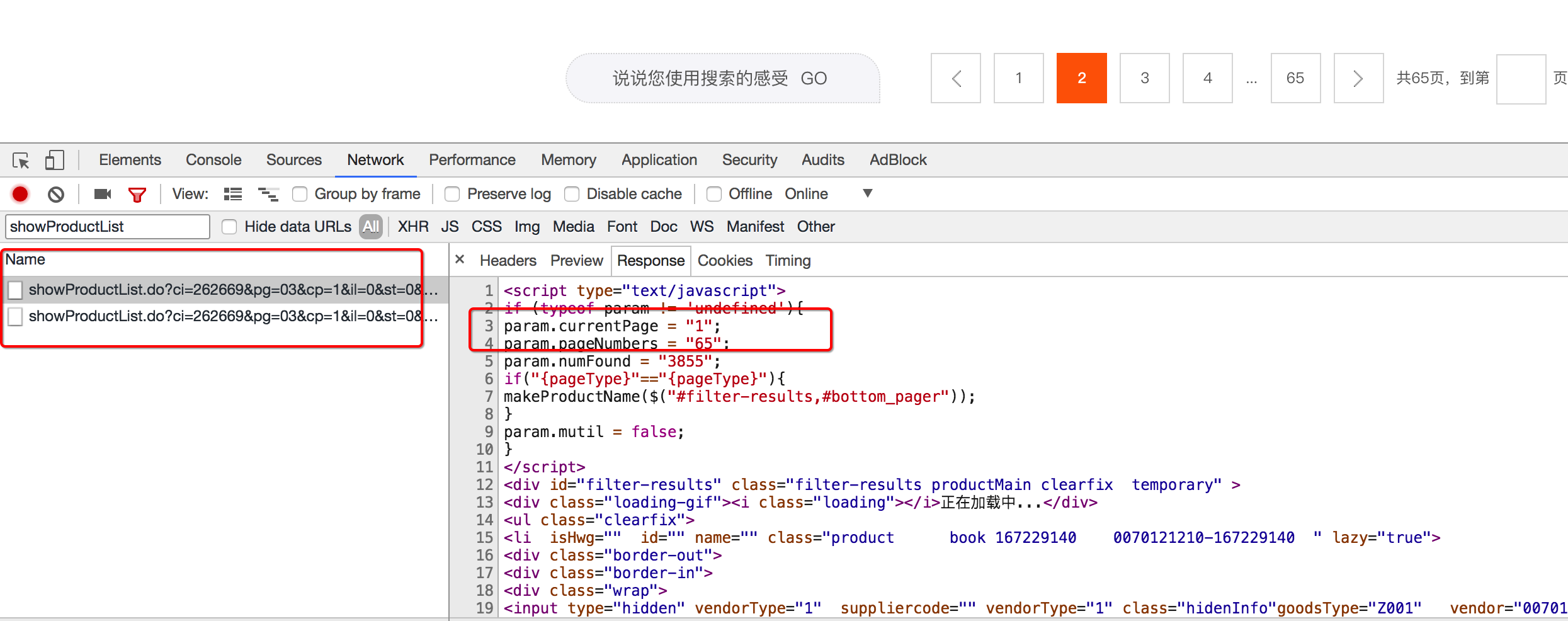
翻页的两个url地址为:
next_url_temp_1 = "https://list.suning.com/emall/showProductList.do?ci={}&pg=03&cp={}&il=0&iy=0&adNumber=0&n=1&ch=4&sesab=ABBAAA&id=IDENTIFYING&cc=010" next_url_temp_2 = "https://list.suning.com/emall/showProductList.do?ci={}&pg=03&cp={}&il=0&iy=0&adNumber=0&n=1&ch=4&sesab=ABBAAA&id=IDENTIFYING&cc=010&paging=1&sub=0"1
2
3其中ci的值和cp的值在变化,ci为url地址中的参数,cp为页码数
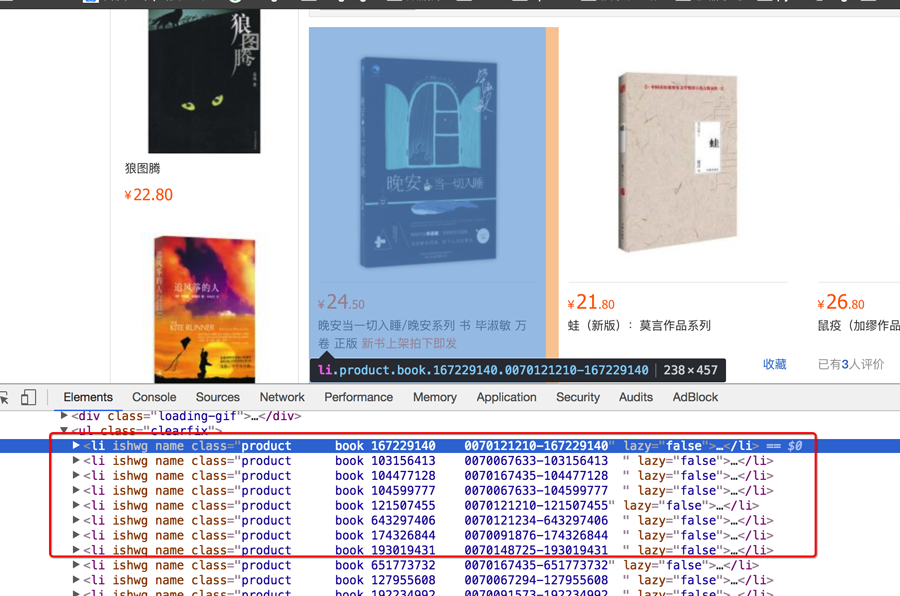
确定列表页数据的位置
列表页的数据都在li标签下,数据都在url地址对应的响应中
但是注意第一页的数据是由小分类的url地址和另一个ajax请求共同获取的,ajax中的数据位置
价格数据的位置 价格不再url地址对应的响应中,而在:
https://pas.suning.com/nspcsale_0_000000000167229140_000000000167229140_0070121210_10_010_0100101_226503_1000000_9017_10106____R9011184_1.1.html?callback=pcData&_=1526313493577这个url地址中的前三个参数在url地址中,后两个参数在详情页url地址的响应中,对应的临时的url地址为:
https://pas.suning.com/nspcsale_0_000000000{}_000000000{}_{}_10_010_0100101_226503_1000000_9017_10106____{}_{}.html?callback=pcData&_=1526011028849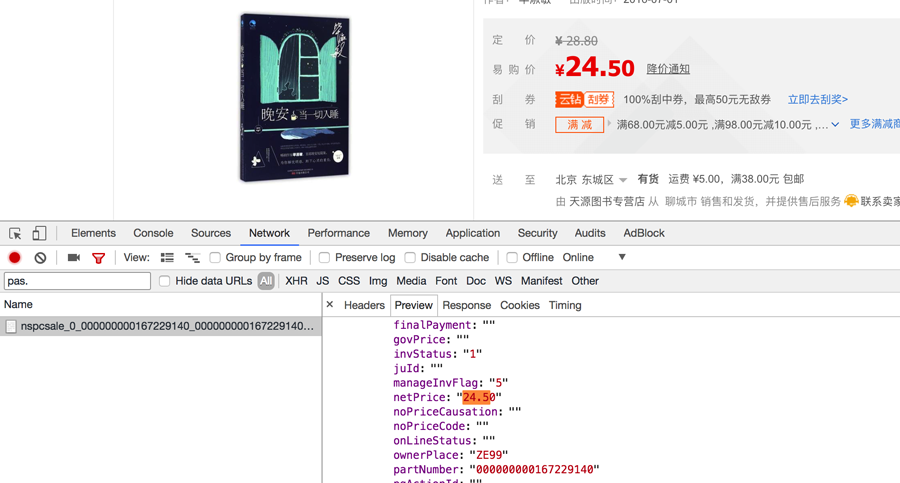
# 小结
- 本小结重点
- 认识scrapy的debug信息
- 知道scrapy shell如何使用
- 认识setting中的配置一起配置的使用