# 3.3. scrapy的入门使用(二)
# 目标
- 掌握如何构造和发送请求
- 掌握Item的使用
- 掌握meta参数的使用
# 1. scrapy实现翻页请求
对于要提取如下图中所有页面上的数据该怎么办?

回顾requests模块是如何实现翻页请求的:
- 找到下一页的URL地址
- 调用requests.get(url)
思路:
- 找到下一页的url地址
- 构造url地址的请求,传递给引擎
# 1.1 实现翻页请求
使用方法
在获取到url地址之后,可以通过
scrapy.Request(url,callback)得到一个request对象,通过yield关键字就可以把这个request对象交给引擎具体使用

添加User-Agent
同时可以再在setting中设置User-Agent:
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36'1通过爬取腾讯招聘的页面的招聘信息,学习如何实现翻页请求
地址:http://hr.tencent.com/position.php (opens new window)
思路分析:
- 获取首页的数据
- 寻找下一页的地址,进行翻页获取数据
# 1.2 scrapy.Request的更多参数
scrapy.Request(url[,callback,method="GET",headers,body,cookies,meta,dont_filter=False])
1
注意:
- 括号中的参数为可选参数
- callback:表示当前的url的响应交给哪个函数去处理
- meta:实现数据在不同的解析函数中传递,meta默认带有部分数据,比如下载延迟,请求深度等
- dont_filter:默认会过滤请求的url地址,即请求过的url地址不会继续被请求,对需要重复请求的url地址可以把它设置为Ture,比如贴吧的翻页请求,页面的数据总是在变化;start_urls中的地址会被反复请求,否则程序不会启动
# 2. 定义Item
定义Item的原因
定义item即提前规划好哪些字段需要抓取,scrapy.Field()仅仅是提前占坑,通过item.py能够让别人清楚自己的爬虫是在抓取什么,同时定义好哪些字段是需要抓取的,没有定义的字段不能使用,防止手误
定义Item

使用Item
Item使用之前需要先导入并且实例化,之后的使用方法和使用字典相同
from yangguang.items import YangguangItem item = YangguangItem() #实例化1
2通过爬取阳光热线问政平台来学习item的使用
目标:所有的投诉帖子的编号、帖子的url、帖子的标题和内容,url: http://wz.sun0769.com/index.php/question/questionType?type=4&page=0 (opens new window)
思路分析
- 列表页的数据
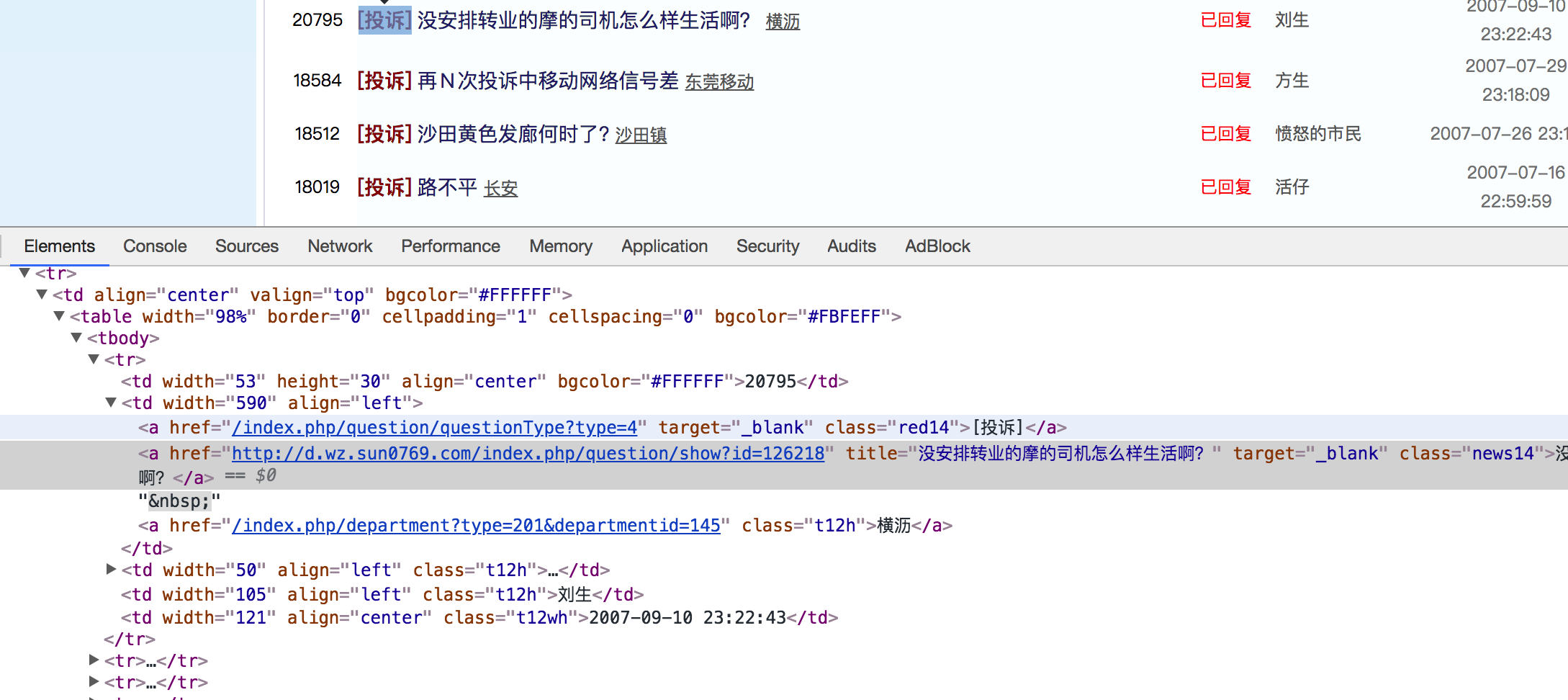
确定列表页url地址和程序结束条件
存在下一页时
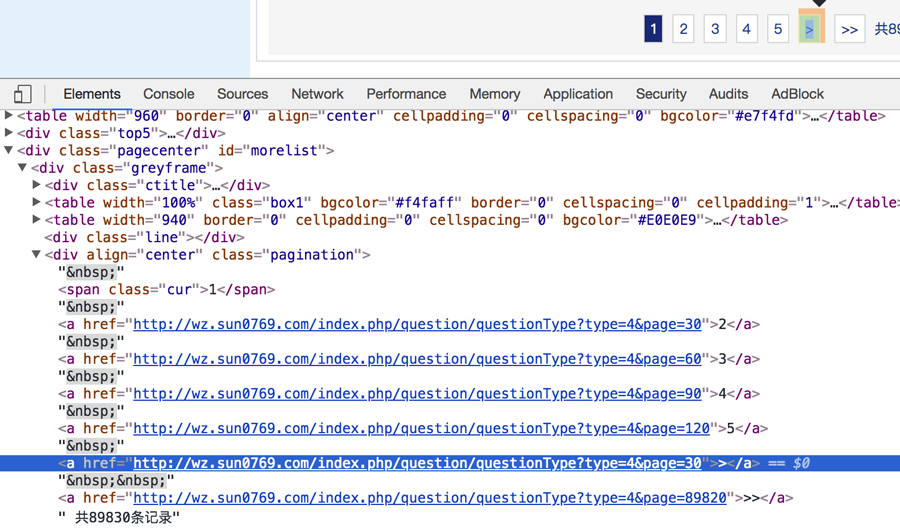
不存在下一页时
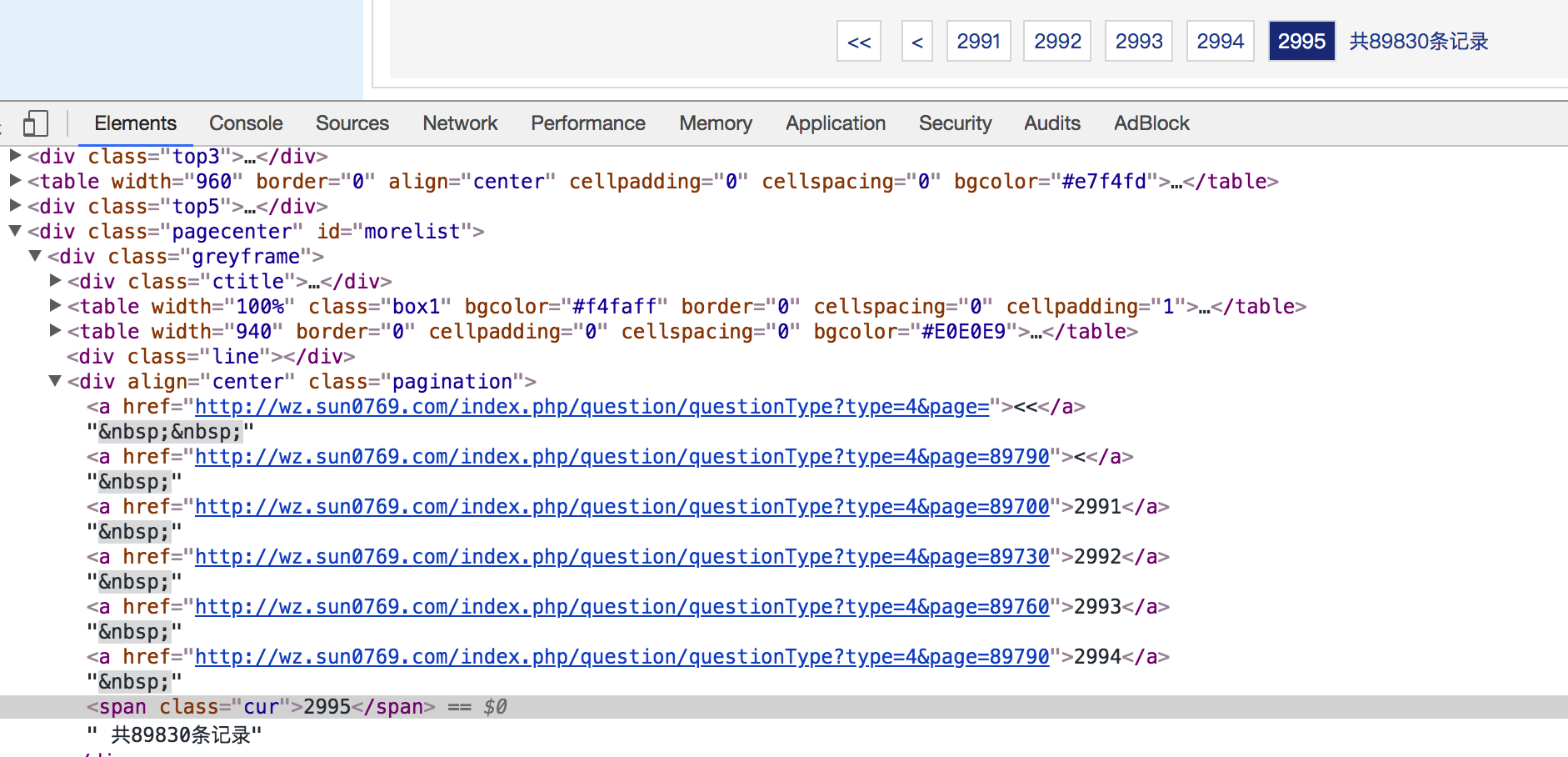
确定详情页的数据
数据从列表页传递到详情页使用:meta参数
包含图片时
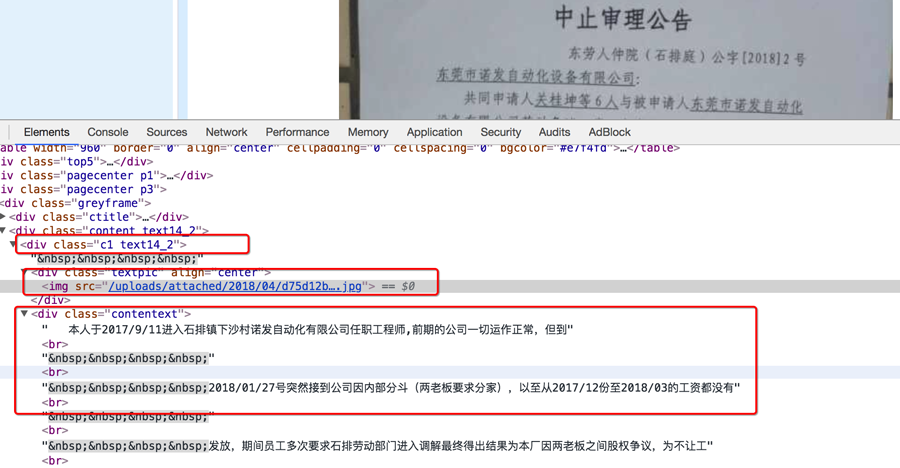
不包含图片时
# 动手
抓取https://www.guokr.com/ask/highlight/上列表页的内容 (opens new window)
# 小结
- 本小结重点
- 掌握scrapy发送请求的方法
- 知道scrapy中dont_filer的使用
- 掌握scrapy中meta参数的使用
- 掌握scrapy中Item的使用