# 4.3. 框架升级 -- 断点续爬设计原理及其实现
# 目标
- 理解断点续爬的内涵
- 理解分布式爬虫中请求丢失的情况
- 理解使用备份队列保留请求的过程
- 完成代码的重构,解决请求丢失的请求
# 1. 断点续爬设计分析
- 断点续爬设计原理介绍:

- 只实现持久化存储队列完成断点续爬可能出现的问题:
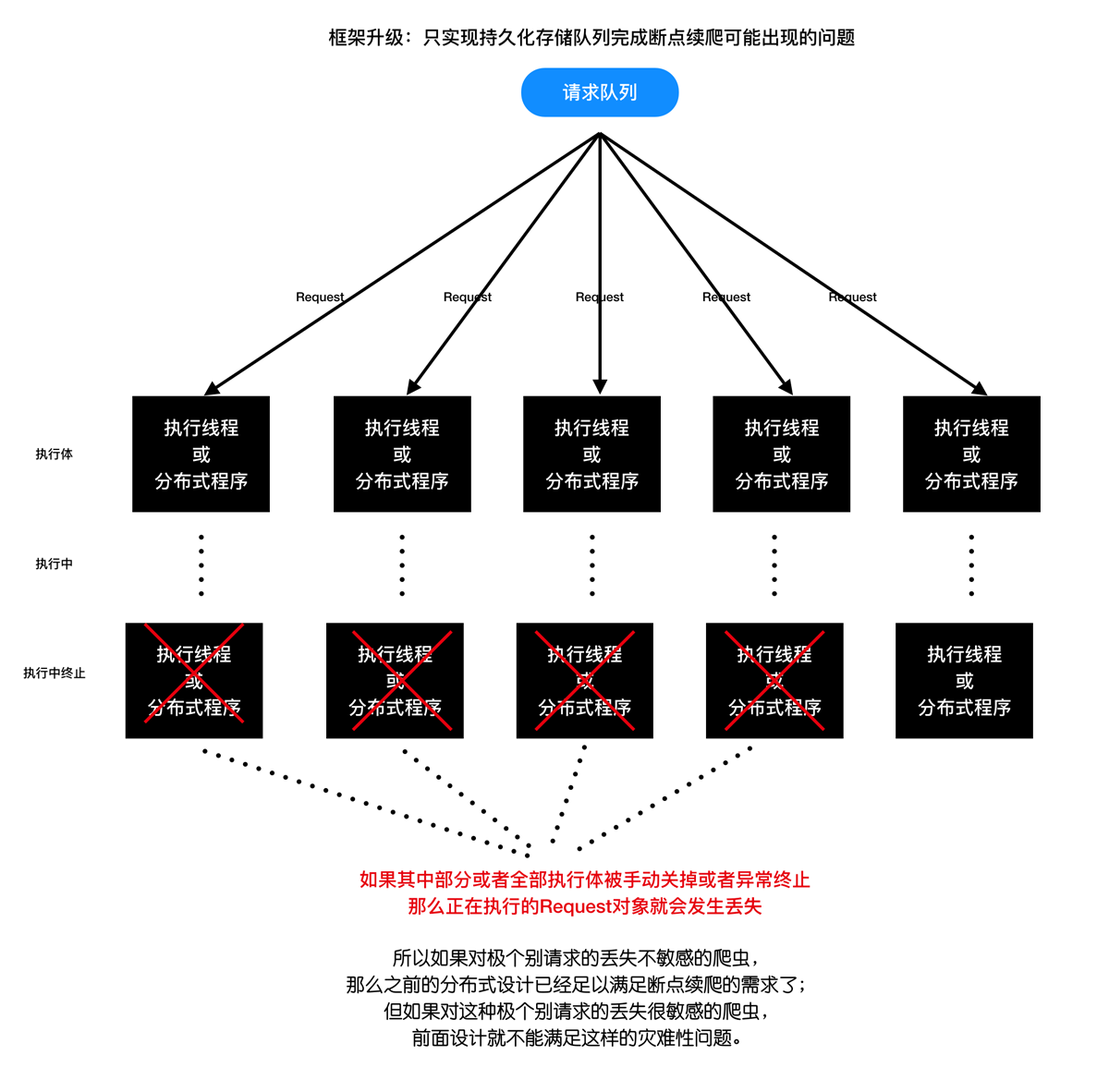
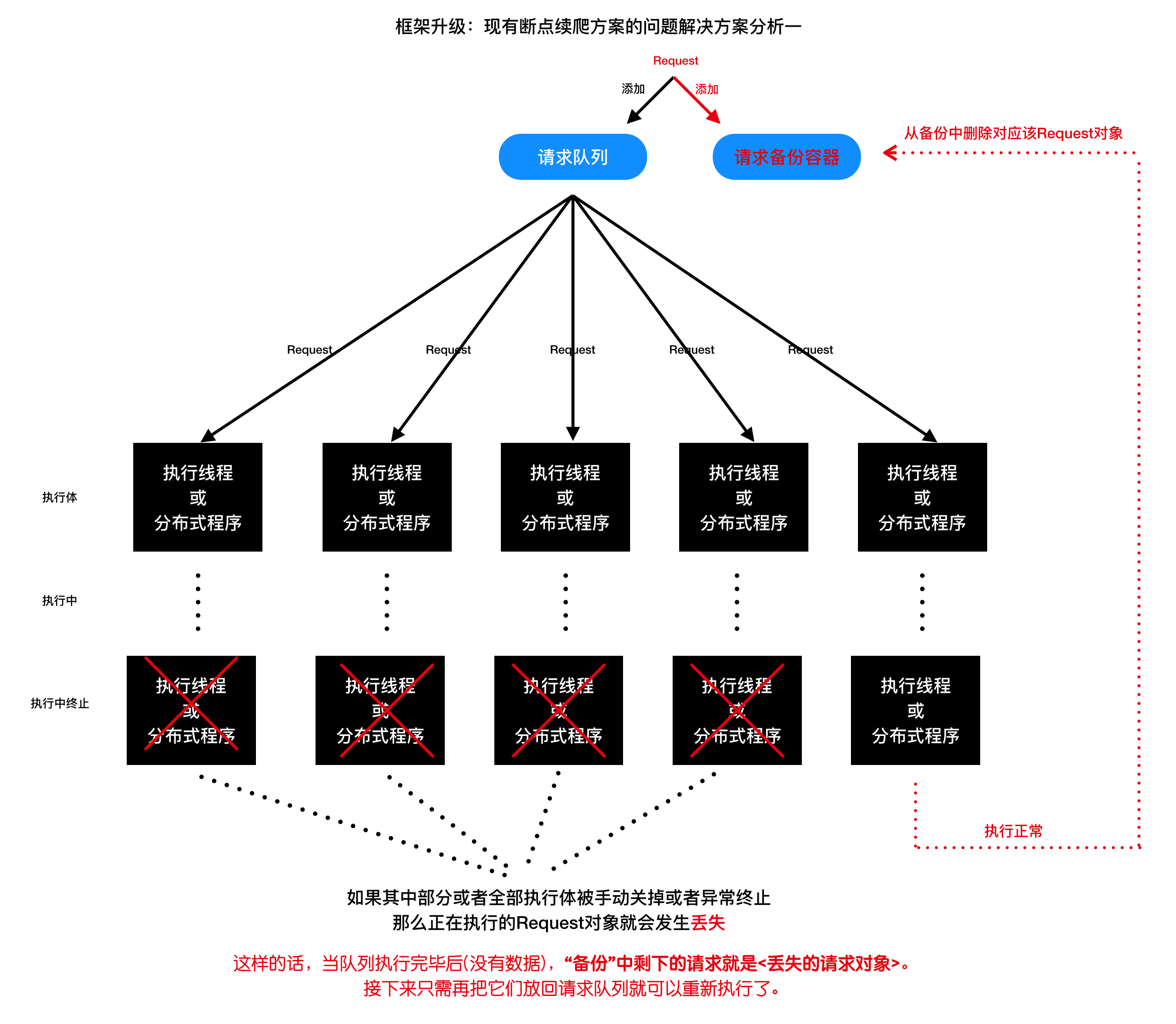
- 现有断点续爬方案的问题解决方案分析一:
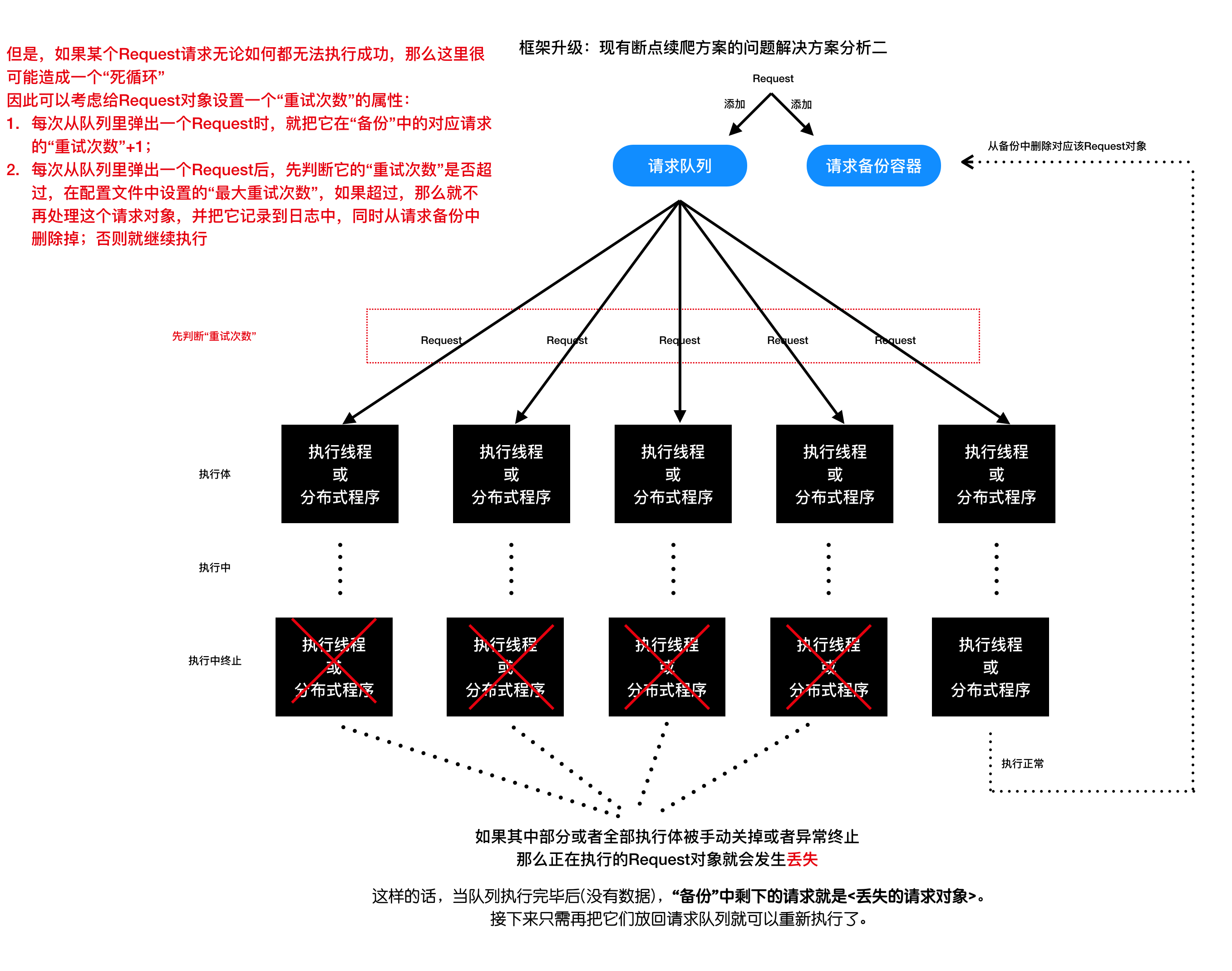
- 现有断点续爬方案的问题解决方案分析二:
# 2. 断点续爬无丢失方案的实现
- 断点续爬无丢失的实现方案分析:
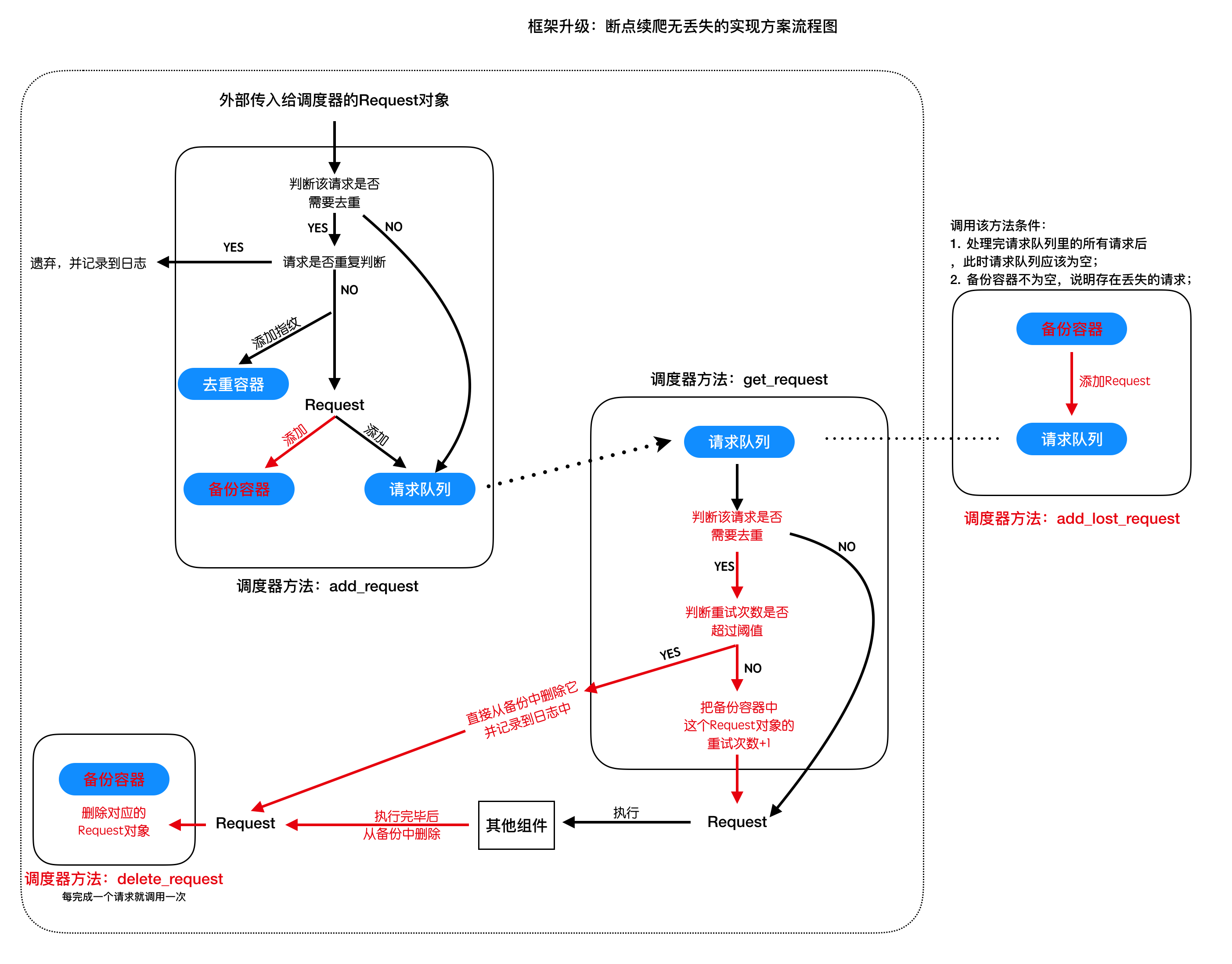
- 断点续爬无丢失的代码实现:
- 添加备份容器:利用redis的hash类型类对每一个请求对象进行存储
- 为Request对象设置重试次数属性
- 在调度器的get_request方法中实现响应的逻辑判断
- 实现delete_request方法:从备份中删除对应的Reqeust对象
- 实现add_lost_request方法
- 在引擎中调用这些方法,完成断点续爬无丢失需求
# scrapy_plus/redis_hash.py
'''实现一个对redis哈希类型的操作封装'''
import redis
import pickle
from scrapy_plus.http.request import Request
from scrapy_plus.conf import settings
class RedisBackupRequest(object):
'''利用hash类型,存储每一个请求对象,key是指纹,值就是请求对象'''
REDIS_BACKUP_NAME = settings.REDIS_BACKUP_NAME
REDIS_BACKUP_HOST = settings.REDIS_BACKUP_HOST
REDIS_BACKUP_PORT = settings.REDIS_BACKUP_PORT
REDIS_BACKUP_DB = settings.REDIS_BACKUP_DB
def __init__(self):
self._redis = redis.StrictRedis(host=self.REDIS_BACKUP_HOST, port=self.REDIS_BACKUP_PORT ,db=self.REDIS_BACKUP_DB)
self._name = self.REDIS_BACKUP_NAME
# 增删改查
def save_request(self, fp, request):
'''将请求对象备份到redis的hash中'''
bytes_data = pickle.dumps(request)
self._redis.hset(self._name, fp, bytes_data)
def delete_request(self, fp):
'''根据请求的指纹,将其删除'''
self._redis.hdel(self._name, fp)
def update_request(self, fp, request):
'''更新已有的fp'''
self.save_request(fp, request)
def get_requests(self):
'''返回全部的请求对象'''
for fp, bytes_request in self._redis.hscan_iter(self._name):
request = pickle.loads(bytes_request)
yield request
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
为Request对象增加重试次数属性:
class Request(object): '''框架内置请求对象,设置请求信息''' def __init__(self, url, method='GET', headers=None, params=None, data=None, parse='parse', filter=True, meta=None): self.url = url # 请求地址 self.method = method # 请求方法 self.headers = headers # 请求头 self.params = params # 请求参数 self.data = data # 请求体 self.parse = parse # 指明它的解析函数, 默认是parse方法 self.filter = filter # 是否进行去重,默认是True self.retry_time = 0 # 重试次数 self.meta = meta1
2
3
4
5
6
7
8
9
10
11
12
13修改调度器,实现对应的逻辑以及方法:
# scrapy_plus/core/scheduler.py ...... from scrapy_plus.redis_hash import RedisBackupRequest ...... class Scheduler(object): ''' 缓存请求对象(Request),并为下载器提供请求对象,实现请求的调度 对请求对象进行去重判断 ''' def __init__(self,collector): if SCHEDULER_PERSIST: #如果使用分布式或者是持久化,使用redis的队列 self.queue = ReidsQueue() self._filter_container = RedisFilterContainer() else: self.queue = Queue() self._filter_container = NoramlFilterContainer() self.collector = collector def add_reqeust(self, request): '''存储request对象进入队列 return: None ''' # 先判断是否要去重 if request.filter is False: self.queue.put(request) logger.info("添加请求成功<disable去重>[%s %s]" % (request.method, request.url)) self.total_request_number += 1 # 统计请求总数 return # 必须return # 判断去重,如果重复,就不添加,否则才添加 fp = self._gen_fp(request) if not self.filter_request(fp, request): # 往队列添加请求 logger.info("添加请求成功[%s %s]"%(request.method.upper(), request.url)) self.queue.put(request) if settings.ROLE in ['master', 'slave']: self._backup_request.save_request(fp, request) # 对请求进行备份 # 如果是新的请求,那么就添加进去重容器,表示请求已经添加到了队列中 self._filter_container.add_fp(fp) self.total_request_number += 1 else: self.repeat_request_number += 1 def get_request(self): '''从队列取出一个请求对象 return: Request Object ''' try: request = self.queue.get(False) except: return None else: if request.filter is True and settings.ROLE in ['master', 'slave']: # 先判断 是否需要进行去重 # 判断重试次数是否超过规定 fp = self._gen_fp(request) if request.retry_time >= settings.MAX_RETRY_TIMES: self._backup_request.delete_request(fp) # 如果超过,那么直接删除 logger.warnning("出现异常请求,且超过最大尝试的次数:[%s]%s"%(request.method, request.url)) request.retry_time += 1 # 重试次数+1 self._backup_request.update_request(fp, request) # 并更新到备份中 return request def delete_request(self, request): '''根据请求从备份删除对应的请求对象''' if settings.ROLE in ['master', 'slave']: fp = self._gen_fp(request) self._backup_request.delete_request(fp) def add_lost_reqeusts(self): '''将丢失的请求对象再添加到队列中''' # 从备份容器取出来,放到队列中 if settings.ROLE in ['master', 'slave']: for request in self._backup_request.get_requests(): self.queue.put(request) ......1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
# 小结
- 本小结重点
- 理解断点续爬的内涵
- 理解分布式爬虫中请求丢失的情况
- 理解使用备份队列保留请求的过程
- 完成代码的重构,解决请求丢失的请求