# 3.3. 数据提取之正则
# 目标
- 掌握正则表达式的常见语法
- 掌握re模块的常见用法
- 掌握原始字符串
r的用法
# 1. 什么是正则表达式
用事先定义好的一些特定字符、及这些特定字符的组合,组成一个规则字符串,这个规则字符串用来表达对字符串的一种过滤逻辑。
# 2. 正则表达式的常见语法
知识点
- 正则中的字符
- 正则中的预定义字符集
- 正则中的数量词
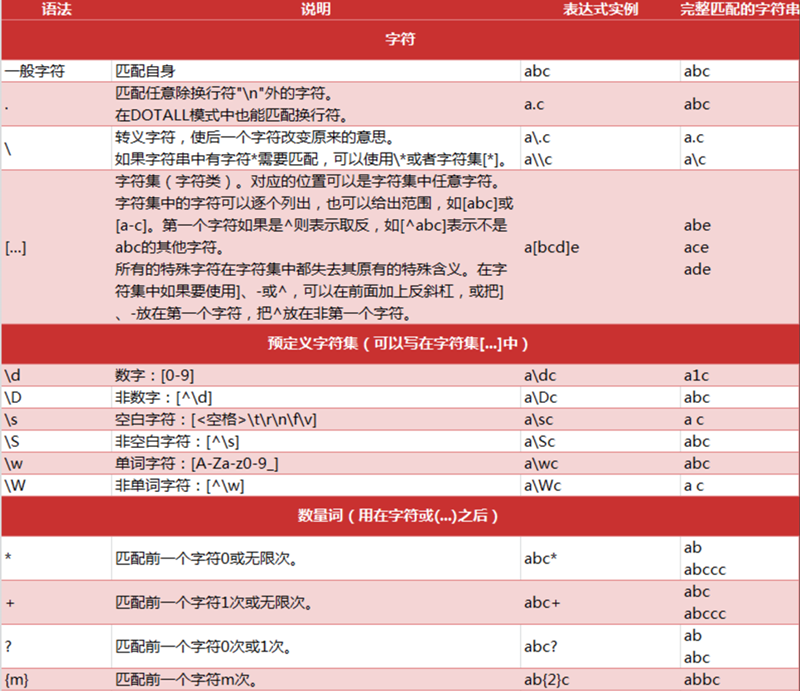
正则的语法很多,不能够全部复习,对于其他的语法,可以临时查阅资料,比如:表示或还能使用|
练习: 下面的输出是什么?
string_a = '<meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1">\n\t\t<meta http-equiv="content-type" content="text/html;charset=utf-8">\n\t\t<meta content="always" name="referrer">\n <meta name="theme-color" content="#2932e1">'
ret = re.findall("<.*>",string_a)
print(ret)
1
2
3
2
3
# 3. re模块的常见方法
pattern.match(从头找一个)
pattern.search(找一个)
**pattern.findall(找所有)**返回一个列表,没有就是空列表
re.findall("\d","chuan1zhi2") >> ["1","2"]pattern.sub(替换)
re.sub("\d","_","chuan1zhi2") >> ["chuan_zhi_"]
re.compile(编译)
返回一个模型P,具有和re一样的方法,但是传递的参数不同
匹配模式需要传到compile中
p = re.compile("\d",re.S) p.findall("chuan1zhi2")1
2
# 4. python中原始字符串r的用法
知识点
- 原始字符串
- 元是字符串的长度
- 原始字符串的使用
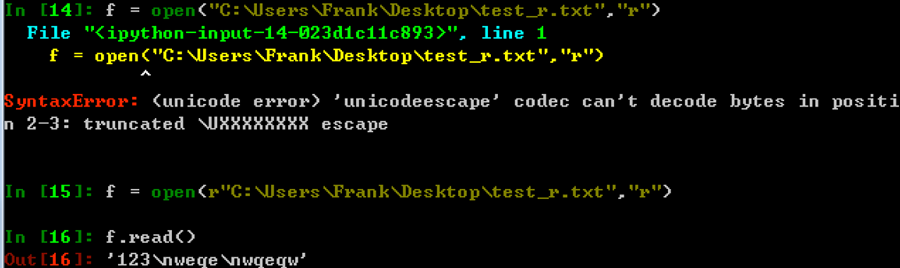
原始字符串定义(raw string):所有的字符串都是直接按照字面的意思来使用,没有转义特殊或不能打印的字符,原始字符串往往针对特殊字符而言。例如"\n"的原始字符串就是"\\n"
原始字符串的长度
In [19]: len("\n") Out[19]: 1 In [20]: len(r"\n") Out[20]: 2 In [21]: r"\n"[0] Out[21]: '\\'1
2
3
4
5
6
7
8正则中原始字符串的使用
In [13]: r"a\nb" == "a\\nb" Out[13]: True In [14]: re.findall("a\nb","a\nb") Out[14]: ['a\nb'] In [15]: re.findall(r"a\nb","a\nb") Out[15]: ['a\nb'] In [16]: re.findall("a\\nb","a\nb") Out[16]: ['a\nb'] In [17]: re.findall("a\\nb","a\\nb") Out[17]: [] In [18]: re.findall(r"a\\nb","a\\nb") Out[18]: ['a\\nb']1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17上面的现象说明什么?
正则中使用原始字符串
r能够忽略转义符号带来的影响,加上原始字符串r之后,待匹配的字符串中有多少个\,正则中就添加多少个\即可
- windows中原始字符串r的使用
# 5. 练习
- re.compile该如何使用?
- 如何非贪婪的去匹配内容?
re.findall(r“a.*bc”,”a\nbc”,re.DOTALL)和re.findall(r“a(.*)bc”,”a\nbc”,re.DOTALL)的区别?不分组时匹配的是全部,分组后匹配的是组内的内容
# 6. 动手
通过正则匹配果壳问答上面的精彩回答的地址和标题:https://www.guokr.com/ask/highlight/?page=1 (opens new window) 思路:
- 寻找url地址的规律
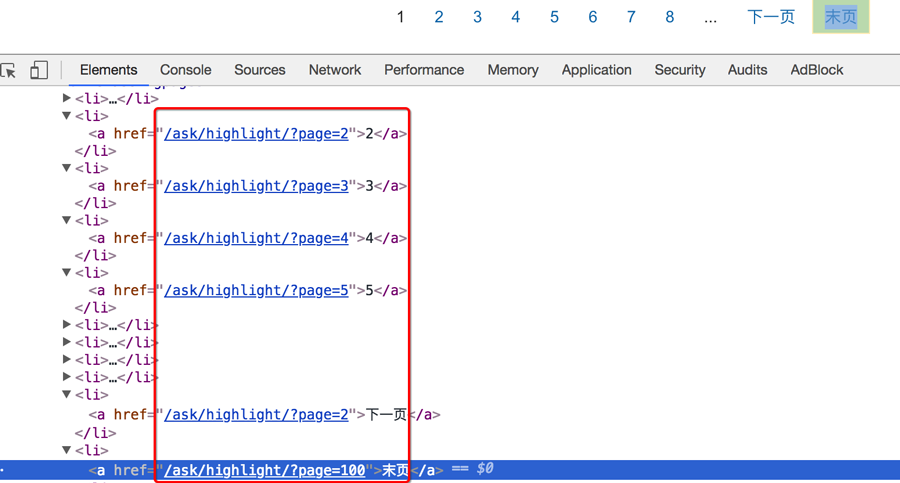
- 寻找数据的位置

- 获取36kr上的所有新闻:http://36kr.com/ (opens new window)
# 小结
- 本小结重点
- 掌握正则表达式的常见语法
- 掌握re模块的常见用法
- 掌握原始字符串
r的用法